Efficient Computing of Deep Neural Network
本文是课程「深度学习的高效计算方法」的笔记,由 余备 教授
Introduction
在 DNN 的实际应用里,无论端侧 (Edge) 还是数据中心侧 (Data Center),实时推理的需求通常达到 ~10fps / 60ms,而一般模型的 Ops / Memory 很多时候都难以满足这一需求,本课程就是在这个领域做调优。课程分为两个 branch: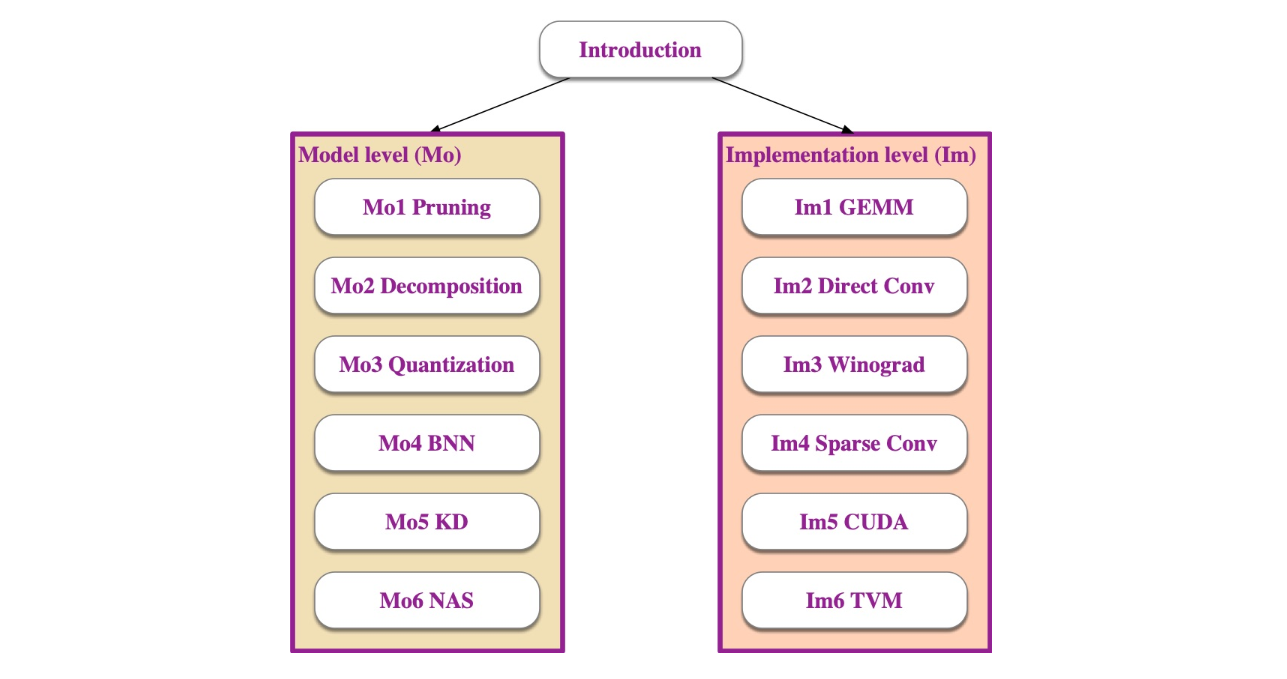
- Model level (Mo): 模型层面,结果可以是不完全对齐的
- Implementation level (Im): 偏工程,对各种算子的实现,要求完全的结果对齐
CNN Architecture Overview
Origin
关于 CNN 算法的前世,我们谈及了:
- LeNet-5
- Perceptron
- MLP: Multi-layer Perceptron (它注定理解能力不强: every pixel-permutation equivariance)
- loss function & automatic differentiation
- GD
- SGD: Stochastic gradient descent (small-batch)
- Old fashion method: 遗传算法, 模拟退火 -> 蚁群算法 etc, 全都是 gradient descent
CNN Basic
关于 CNN 的一些基础知识,我们谈及了:
- CNN
- ReLU
- ImageNet
- AlexNet
- Maxpooling better
- Dropout regularization better
- CV
- Classification/Detection/Segmentation/Sequence
Resent History
关于近年来 CNN 的崛起,我们谈及了:
- Winter: mid 90s - 2006 (SVM & Random forest better, No theory, no data, benchmark insensitive, optimization, hard to repreduce)
- Renaissance: 2006- (Nvidia GPU, Microsoft's achievement in Speech, AlexNet in Image)
- Revolution of Depth: AlexNet 8 -> VGG 19 -> ResNet 152
- Recent Classification: MobileNetV2, 2018 & ShuffleNet, 2018 (size smaller)
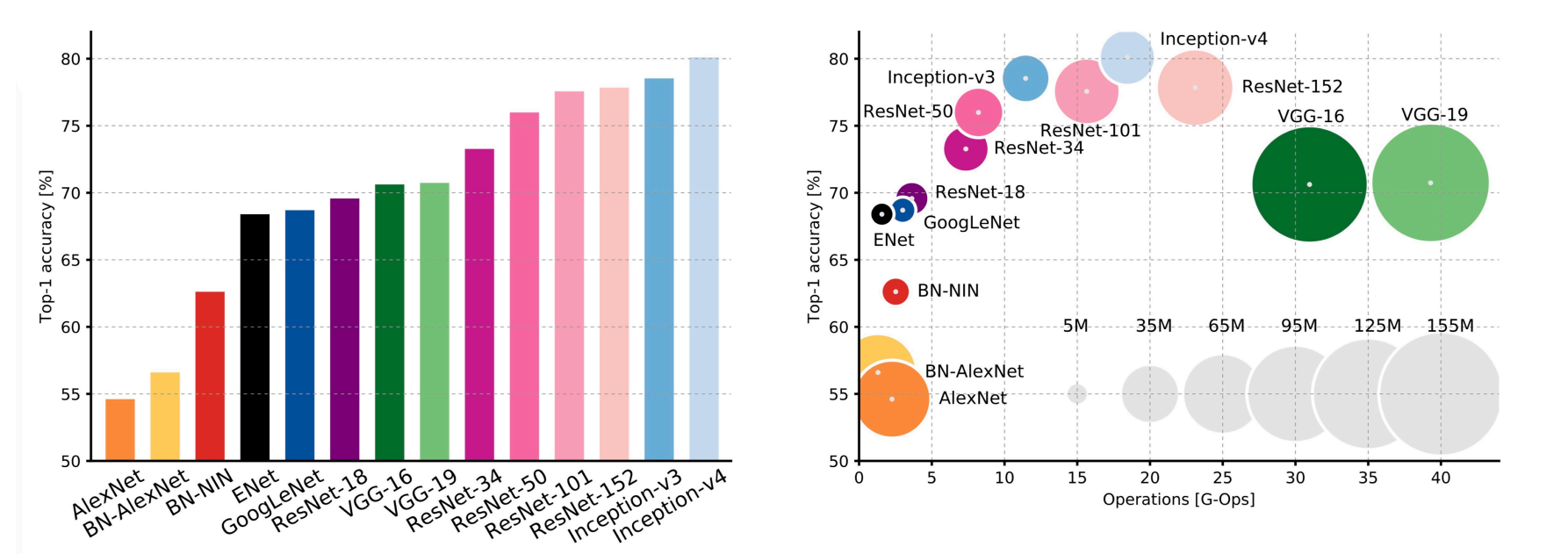
- Why AlexNet & VGG bigger but less operations? FC layer 4096*4096 + 4096*1000
- 腾讯的 AI lab 说如果想让模型跑在端侧上,模型不能够有 FC layer;对于这样的分类任务如何避免出现 FC?这样的讨论发生在 19-20 年,大家觉得合理的 Pooling 可以代替最后分类的FC。现如今 Conv layer 占据计算的接近 90%.
- Example: Hisense ADAS, 双目视觉自动驾驶通过一块后置 Nvidia GPU 在车上部署
CNN on Embedded Platform
近年端侧平台 CNN 的市场情况:
- Machine Learning on Hardware
- Conv layer is one of the most expensive layer
- More and more end-point devices with limited memory
- Google TPU (Tensor Processing Unit, an ASIC)
- Qualcomm NPU
- Apple Neural Engine
- Xilinx (AMD) FPGA
- Altera (Intel) FPGA
- Mobileye
- HiSilicon (Huawei)
- VeriSilicon IP (卖半导体解决方案知识产权的)
- Challenges:
- Model Size
- Energy Efficiency
- (Flexibility) -> CPU / GPU / FPGA / ASIC -> (Power/Performance Efficiency)
- GPU: specific for matrix/tensor
- FPGA: computation unit fixed, but connection programable
- ASIC: all computation fixed
- GPU dominate!
Im1: GEMM
GEMM, General Matrix Multiplication, 本节我们从矩阵乘的访存优化角度,讲解 Im2col, MEC 两种加速方法,并讨论它们对应的 Memory Layout 策略。
Recap: 卷积层的输出 feature map \displaystyle h^\prime=\frac{h-r+2\cdot \text{pad}}{\text{stride}}, \displaystyle w^\prime=\frac{w-r+2\cdot \text{pad}}{\text{stride}}, 输入 feature map shape (B, C, H, W) 作用在 K 个 filter 上得到 (B, K, H^\prime, W^\prime), 第 i 个 channel 的结果是 1 个 filter 的 C 张 kernel (不同) 一一对应地作用在 C 张 image 的结果的 和
Im2Col
Recap
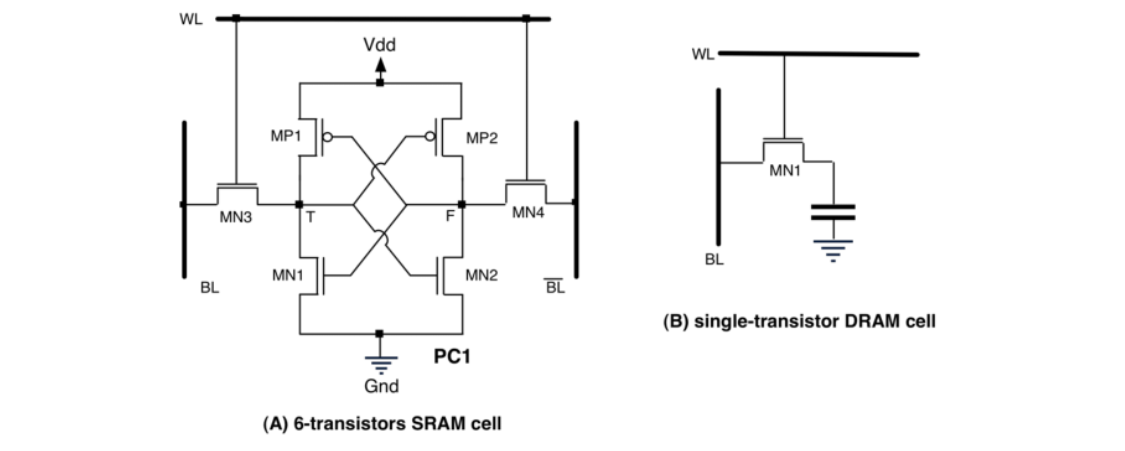
- MOS 是一个 Transistor
- Invertor 需要 2 个 Transistor
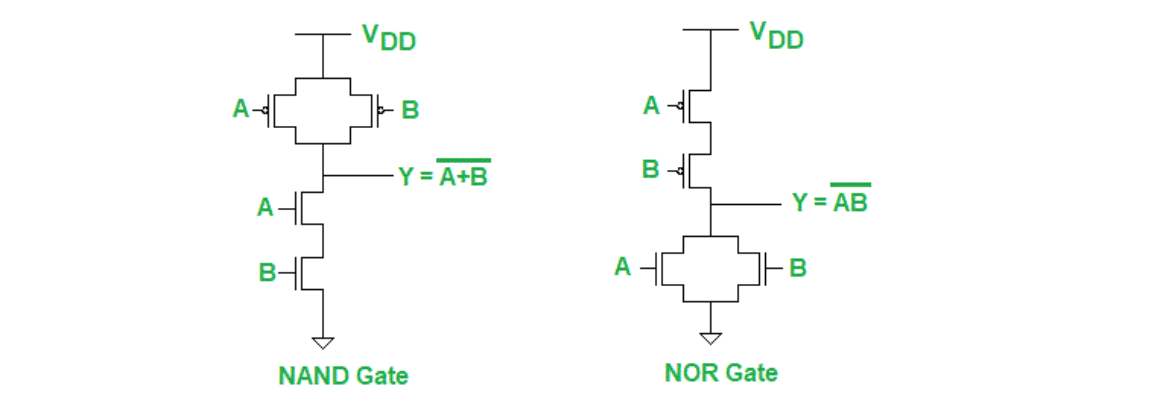
- NAND 和 NOR 都需要 4 个 Transistor
- SRAM 介于 CPU 和 DRAM 之间
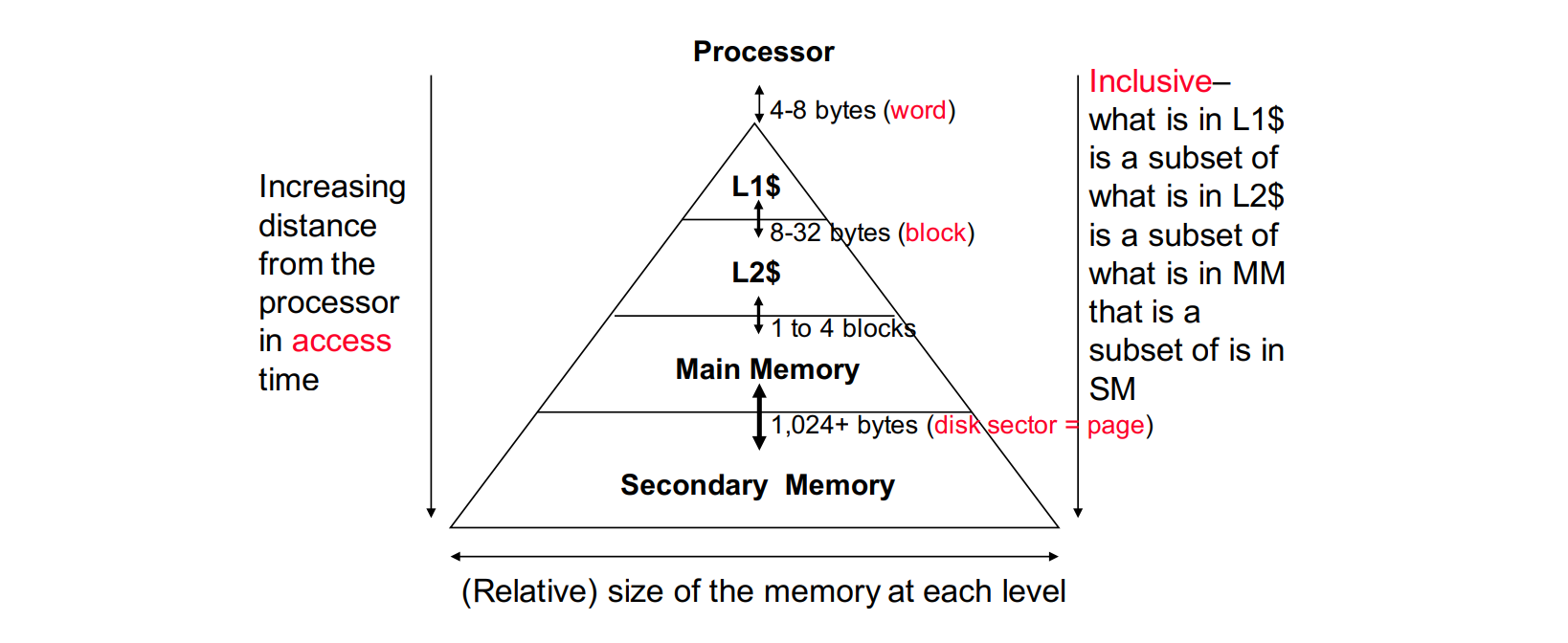
- spatial locality (在不远的将来引用附近的一个内存位置) 和 temporal locality (被引用过一次的内存位置很可能在不远的将来再被多次引用)
- Memory System
For Spatial Locality...
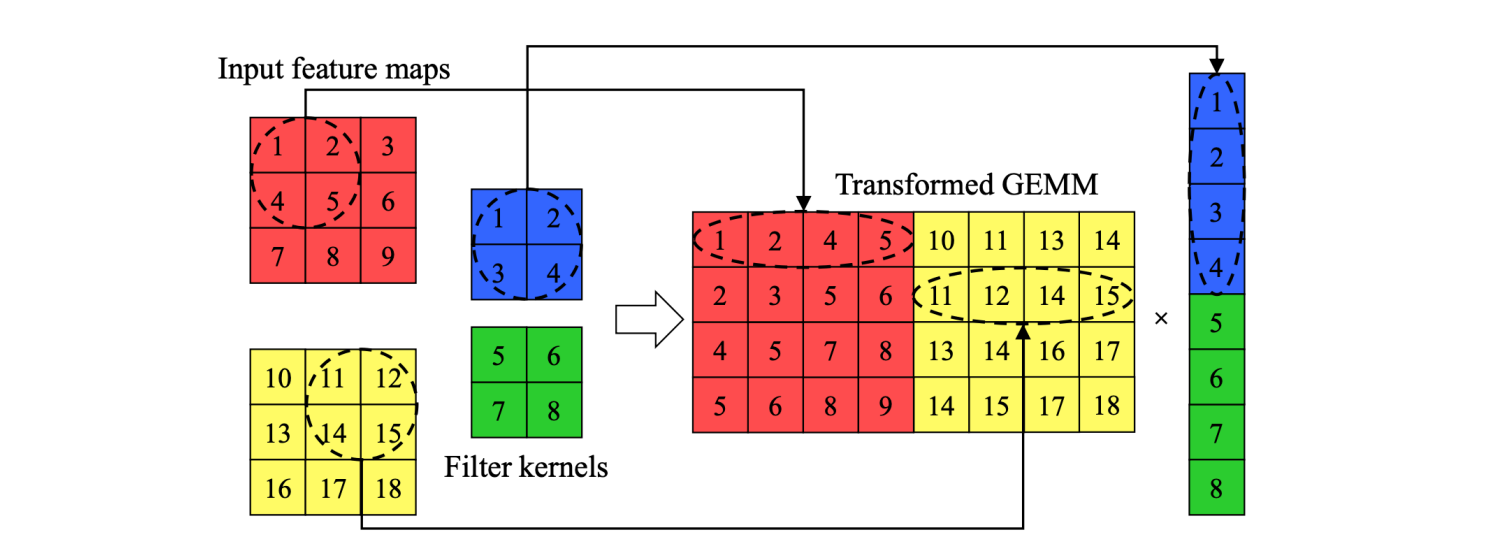
Im2Col 把矩阵按照 kernel 划分转成行,好处是满足 Spatial Locality 带来好的访存性能 (BLAS-friendly & SIMD parallel) 且天然支持 3D-Convolution,将 3D-Conv 统一转换成了矩阵乘;缺点是 duplicate 太多 (most ~k^{2}) 占用内存太大,接下来我们试着解决这个问题.
BLAS (Basic Linear Algebra Subprograms): 一套定义了基本线性代数运算(如向量点乘、矩阵-向量乘法、矩阵-矩阵乘法)标准接口的规范。它是科学计算和高性能计算库(如 Intel MKL, OpenBLAS, ATLAS, cuBLAS)的基石。BLAS-friendly: 指数据在内存中的排列方式能够高效地被这些优化过的 BLAS 库利用。
SIMD (Single Instruction, Multiple Data) 一种 CPU 硬件并行技术。一条指令可以同时对多个数据元素执行相同的操作。例如,一条 SIMD 加法指令可以一次性完成 4 个单精度浮点数(float)或 2 个双精度浮点数(double)的加法。通过 CPU 的特殊寄存器(如 x86 的 SSE/AVX/AVX-512 寄存器, ARM 的 NEON/SVE 寄存器)和对应的指令集实现。这些寄存器比通用寄存器宽得多(128位, 256位, 512位, 甚至更多)。
Memory-Efficient Conv (MEC, ICML 2017)
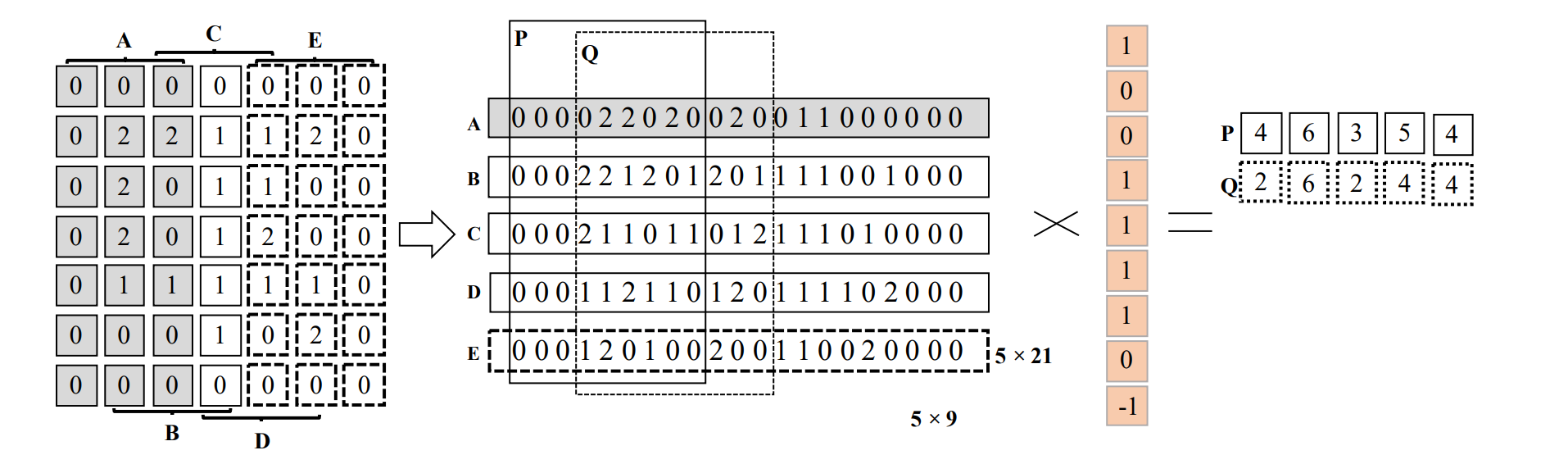
MEC 最多复制 ~k 次,缺点是 spatial locality 没那么强,并且需要额外的转置带来性能损失
Memory Layout
以 feature map 的 2 种存储方式为例,这同样是一个 tradeoff
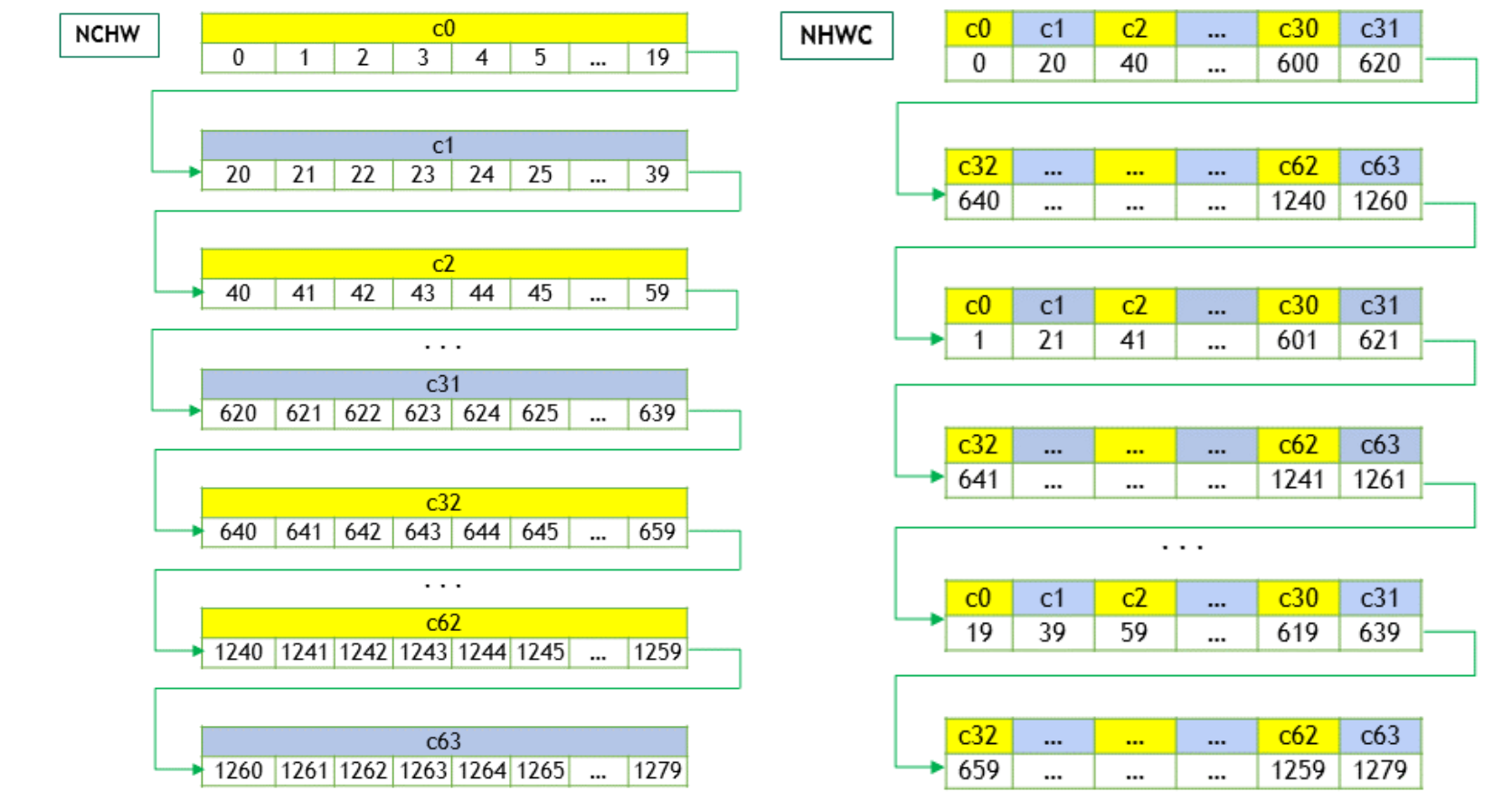
Most TensorFlow operations used by a CNN support both NHWC and NCHW data format. On GPU, NCHW is faster. But on CPU, NHWC is sometimes faster.
又以 3 种 GEMM 加速方法为例
- Im2col 显式地转换并存储巨大的展开的二维矩阵
- MEC 与前例相同将数据组织为
(Output_H * Output_W * Batch, C * K_h * K_w),但并不物理上创建这个矩阵,例如计算A * B时,当需要访问B矩阵的一小块 (KC x NC或类似分块) 时,不是从一个大矩阵中读取,而是动态地从原始输入特征图 (NCHW / NHWC) 中按卷积窗口规则提取 (KC x NC) 所需的数据到一个小的临时缓冲区中。 - MNN 是一个针对移动应用量身定制的通用高效推理引擎,将 (H, W) 划分为 4x4 的块 (Tile),对于一个 Tile 内的所有通道 (C),将数据按通道优先的方式连续存储;这样在部分保留 spatial locality 的同时消除了 im2col 的巨大开销和 MEC 中复杂的运行时数据收集/地址计算。
Im2: Direct Convolution
本节我们仍然从访存的角度,通过修改运算过程讨论 Loop Reordering, Unrolling, Tilling, Dataflow 几种卷积计算的优化方式
Loop Reordering
Conv1d Example

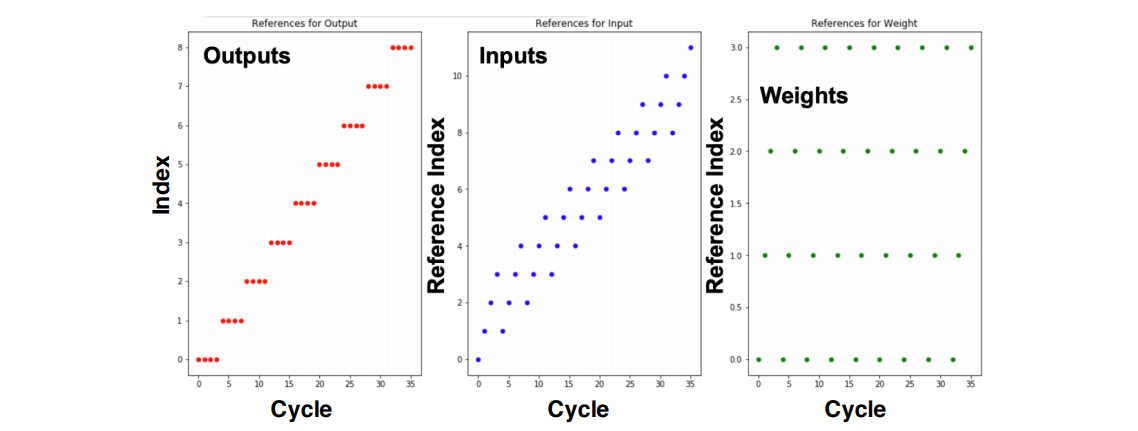
- Output Stationary 的访存情况
- Weight Stationary 的访存情况
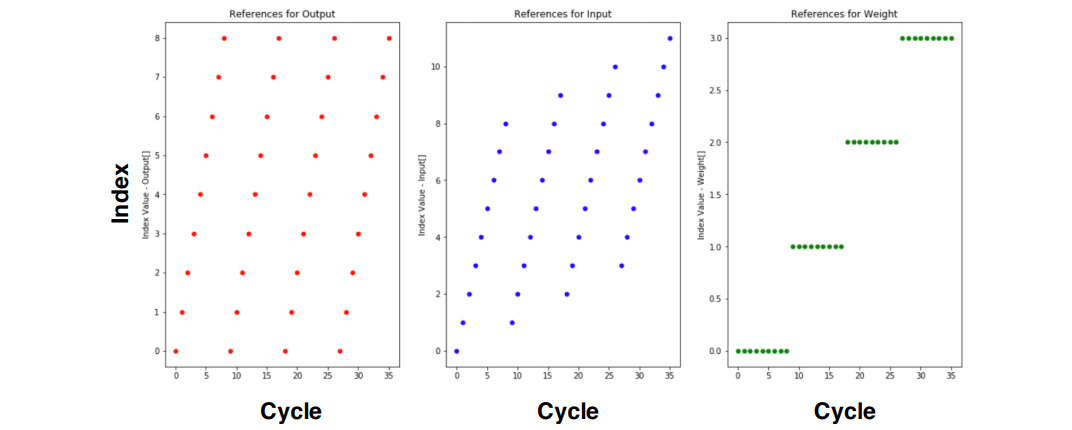
是一个比较艰难的 tradeoff,在课堂测试环境下 WS 速度更快
Conv2d Example
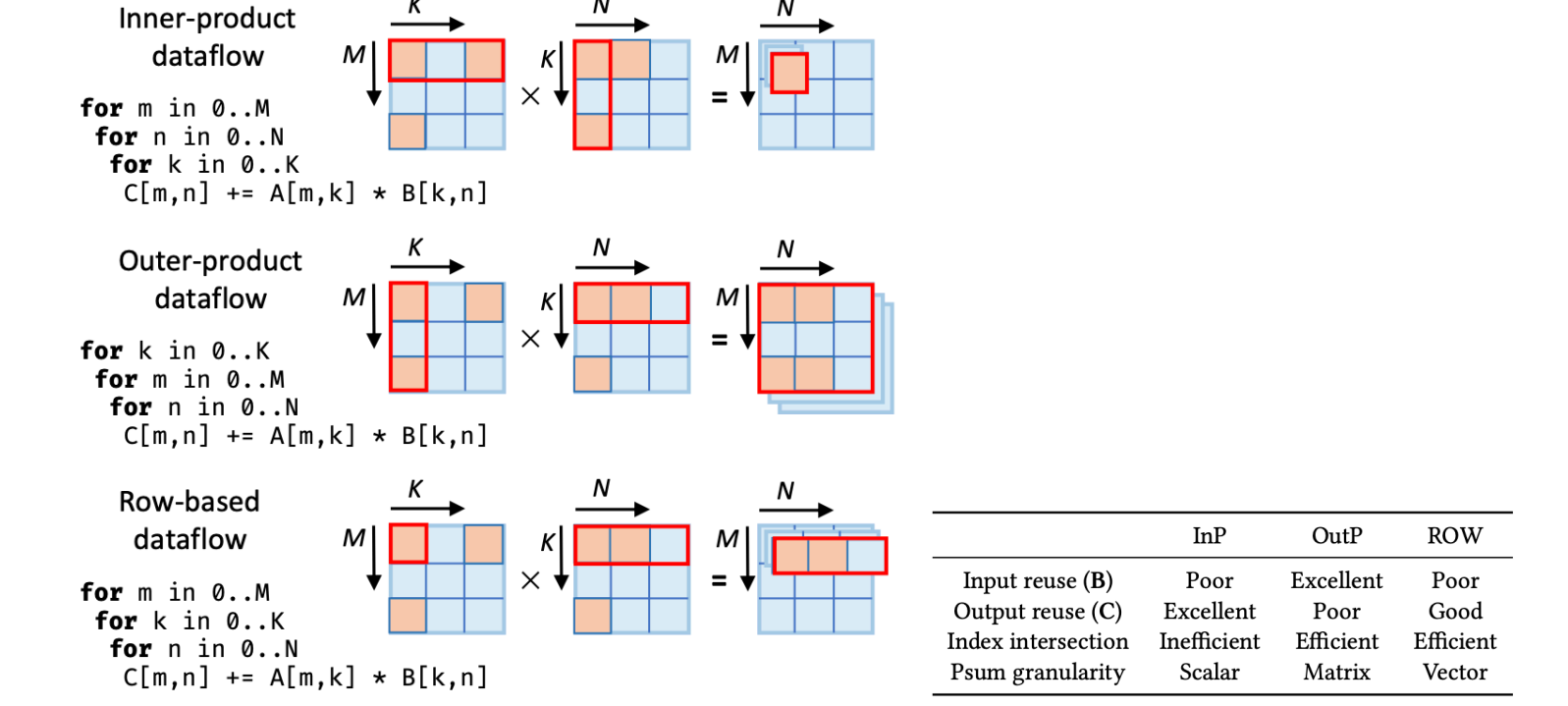
在 6 种模式里这 3 种是比较好的,课堂测试环境下 ROW < OutP << InP
Direct Convolution
- Loop Reordering 策略:如上所述,通过调整 for loop 顺序满足更好的 parallel 和 locality 获得更好的矩阵乘性能
- Unrolling 策略:展开某个 for loop 为一次迭代,减少分支和循环开销,增加 parallel 机会
- Tilling 策略:通过划分展开某个 for loop 为更多的 for loop,使其一次迭代所需数据能尽量保留在 cache 中

Dataflow Optimization
我们考虑在矩阵乘的过程中,存在强的传输 bound;据此,NVidia 的 TensorCore 和 Google, TPU 都使用了 systolic array 方法处理矩阵乘 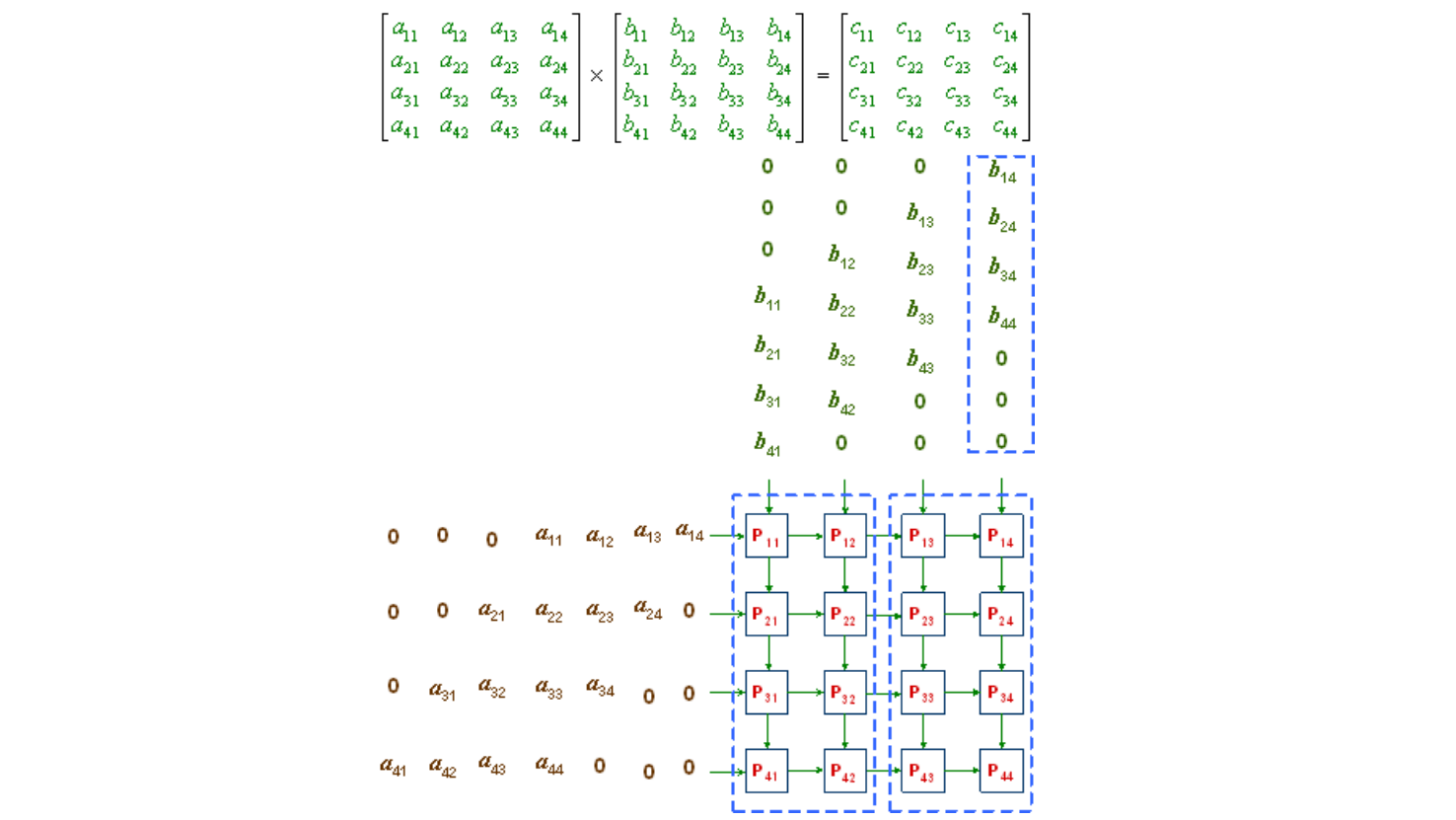
大大突破了传输 bound,虽然拖慢了计算的速度,这是一种近存计算

Im3: Winograd
首先初始化寄存器:
- 乘数寄存器(Multiplier Register - MR): 存储乘数 B (4位)。
- 被乘数寄存器(Multiplicand Register - MDR): 存储被乘数 A (4位)。
- 乘积寄存器(Product Register - PR): 初始化为0。这个寄存器需要8位宽,因为两个4位数相乘最大结果是15 * 15=225(11100001),需要8位表示。
- 计数器(Counter - C): 初始化为乘数的位数(这里是4)。
核心循环(重复4次):
- 检查乘数最低有效位(LSB):使用ALU的逻辑功能(通常是AND操作或直接访问)检查MR寄存器当前最低位是0还是1。
- 如果LSB == 1:将被乘数寄存器(MDR) 的值加到乘积寄存器(PR) 的高4位(或整个PR,取决于设计)上。这一步使用ALU的加法功能。
- 如果LSB == 0:不进行加法操作(相当于加0)。
- 右移乘数寄存器(MR):将MR寄存器逻辑右移一位。最低位移出,最高位补0。这使用ALU的移位功能(或专门的移位器)。移出的那位(原LSB)决定了上一步是否进行加法。
- 右移乘积寄存器(PR):将整个PR寄存器(8位)算术右移或逻辑右移一位(对于无符号乘法,逻辑右移即可)。最高位补0,最低位移入MR移位后空出的最高位(或者根据具体设计,可能移入进位标志,但在基本版本中通常简单补0)。这一步也使用ALU的移位功能。
- 递减计数器(C):计数器减1(通常使用ALU的减法功能或专门的计数器逻辑)。
- 检查计数器:如果计数器 C > 0,则跳回步骤 a 开始下一次迭代。如果计数器 C == 0,则循环结束。
循环结束后,乘积寄存器(PR) 中存储的8位值就是乘法运算的结果 A * B。
作为一个导入,我们稍作观察一个 4-bit ALU (算术逻辑单元) 进行移位-加法乘法 (Shift-and-Add Multiplication) 的方式。它具体如何执行并不重要,主要是,非常复杂!可以想见它要占据很大的时间开销,因此,本节的主要目的是讨论 Strassen 和 Winograd 方法来 减少卷积过程中的乘法。
Strassen
1. Time Complexity
熟悉渐进符号的定义:
- 渐进上界 f=\mathcal{O}(g) if \displaystyle \lim_{ n \to \infty } \frac{f(n)}{g(n)}<\infty
- 渐进下界 \displaystyle f=\Omega(g) if \displaystyle \lim_{ n \to \infty } \frac{f(n)}{g(n)}>0
- 渐进时间复杂度 \displaystyle f=\Theta(g) if \displaystyle \lim_{ n \to \infty } \frac{f(n)}{g(n)}=c, note \displaystyle \Theta(g)=\mathcal{O}(g) \land \Omega(g)
并有主定理 (Master Theorem):
设 T(n) 是一个单调递增函数,满足:
T(n) = \left\{\begin{align} & c, & \text{if } N = 1; \\ & aT\left(\frac{n}{b}\right) + f(n), & \text{if } N > 1. \end{align}\right.其中 a \geq 1, b \geq 2, c > 0。如果 f(n) \in \Theta(n^d) 且 d \geq 0,那么:
T(n) = \left\{ \begin{align} & \Theta(n^d), & \text{if } a < b^d \\ & \Theta(n^d\log n), & \text{if } a = b^d \\ & \Theta(n^{\log_b a}), & \text{if } a > b^d \end{align} \right.
2. Multiplication
- 普通的矩阵乘是 \displaystyle \mathcal{O}(N^3) 的
- 递归的矩阵乘
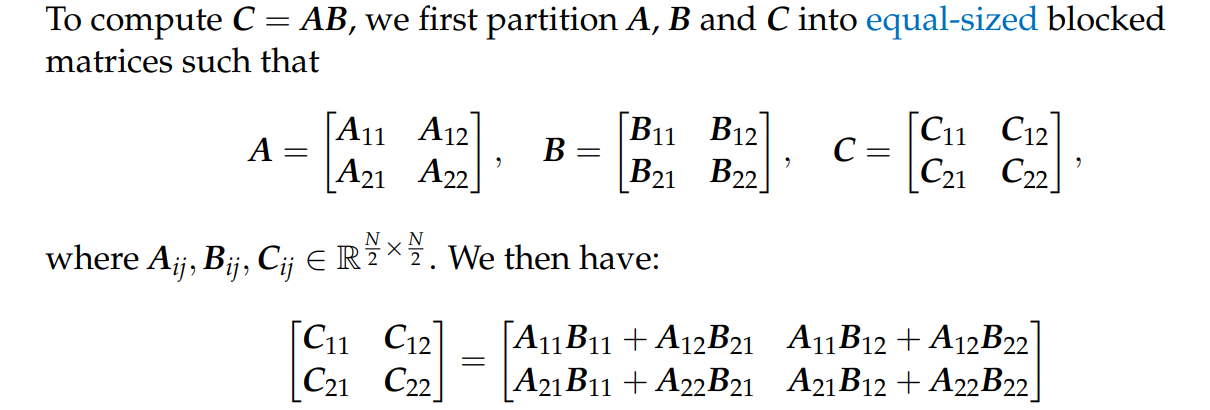 根据 Master Theorem 有 \displaystyle T(N)=\left\{ \begin{aligned} &\Theta(1), & \text{if} N=1; \\ &8T\left( \frac{N}{2} \right)+\Theta(N^{2}), &\text{if} N>1. \end{aligned}\right.,从而递归算法同样是 \displaystyle \Theta(N^3) 的
根据 Master Theorem 有 \displaystyle T(N)=\left\{ \begin{aligned} &\Theta(1), & \text{if} N=1; \\ &8T\left( \frac{N}{2} \right)+\Theta(N^{2}), &\text{if} N>1. \end{aligned}\right.,从而递归算法同样是 \displaystyle \Theta(N^3) 的
3. Strassen Algorithm
Define: \displaystyle {\begin{aligned}M_{1}&=(A_{11}+A_{22}){\color {red}\times }(B_{11}+B_{22});\\M_{2}&=(A_{21}+A_{22}){\color {red}\times }B_{11};\\M_{3}&=A_{11}{\color {red}\times }(B_{12}-B_{22});\\M_{4}&=A_{22}{\color {red}\times }(B_{21}-B_{11});\\M_{5}&=(A_{11}+A_{12}){\color {red}\times }B_{22};\\M_{6}&=(A_{21}-A_{11}){\color {red}\times }(B_{11}+B_{12});\\M_{7}&=(A_{12}-A_{22}){\color {red}\times }(B_{21}+B_{22}),\\\end{aligned}}
Then, \displaystyle {\begin{bmatrix}C_{11}&C_{12}\\C_{21}&C_{22}\end{bmatrix}}={\begin{bmatrix}M_{1}+M_{4}-M_{5}+M_{7}\quad &M_{3}+M_{5}\\M_{2}+M_{4}\quad &M_{1}-M_{2}+M_{3}+M_{6}\end{bmatrix}}.
Time Complexity: \displaystyle O([7+o(1)]^{n})=O(N^{\log _{2}7+o(1)})\approx O(N^{2.8074})
Strassen 矩阵乘并没有得到很好的应用,这是因为完全牺牲了访存性能。
Winograd
1. Conv1d
在 filter 长度为 r, 输出长度为 m (称为 F(m,r)) 时,Winograd 将乘法次数 \displaystyle \mu(F(m, r)) 从 \displaystyle m*r 优化到 m+r-1.
一般形式而言,Winograd 将 F(2,3) 优化到 4 次乘法:
其中,
矩阵形式而言,Y = A^T [(Gg) \odot (B^T d)]
在 F(2,3) 的情形下,
多项式乘法的本质是多项式系数的卷积。一个域中的卷积可以等价为另一个域中的乘法。B,G,A 实际是到另一个域的变换矩阵,变换之后卷积就可以以乘法的方式体现。
2. Conv2d
Conv2d 可以通过分块转换为 Conv1d winograd 
3. Application
Winograd 并没有受到很广泛的礼遇,问题是:
- 并不完全 GPU-Friendly,场景受限
- 访存性能有一定损失
- 对于不同的 kernel 需要各自的 B,G,A,从而运算过程需要客制化
- 适用于 FPGA 而非 ASIC
Mo1: Pruning
Linear Regression Optimization
- 范数 Norm: L-p norm \displaystyle ||x||_{p}=\left( \sum_{i}|x_{i}|^{p} \right)^{ \frac{1}{p} }
- 线性回归 Linear Regression
- 目标 Objective (Least Square): \displaystyle \min_{\beta}||\boldsymbol{y}-\boldsymbol{X}\boldsymbol{\beta}||^{2}_{2}
- 问题 Challenges: Overfitting
- 训练方法: Local Analysis \displaystyle S_{i}= \frac{f(x_{1}, \dots, x_{i}+\Delta x_{i}, x_{k})-f(x_{1},\dots,x_{k})}{\Delta x_{i}} | Least Square \displaystyle \boldsymbol{\beta}=(\boldsymbol{X}^{\top}\boldsymbol{X})^{-1}\boldsymbol{X}^{\top}\boldsymbol{y}
- 正则化 Regularization
- \displaystyle \mathscr{l}_{0}-Norm Regularization: subject to \displaystyle ||\boldsymbol{\beta}||_{0}\leq \lambda, 不怎么用是因为优化它是 NP hard 的
- \displaystyle \mathscr{l}_{2}-Norm Regularization / Ridge Regression: \displaystyle \min_{\beta}||\boldsymbol{y}-\boldsymbol{X}\boldsymbol{\beta}||^{2}_{2}+\lambda \sum_{j=1}^{p}|\beta_{j}|^{2} -> \displaystyle \boldsymbol{\beta}=(\boldsymbol{X}^{\top}\boldsymbol{X} + \lambda \boldsymbol{I})^{-1}\boldsymbol{X}^{\top}\boldsymbol{y}
- \displaystyle \mathscr{l}_{1}-Norm Regularization / Lasso: \displaystyle +\lambda \sum_{j=1}^{p}|\beta_{j}|, 可以产生 sparsity
- More regularization term...: \displaystyle |x|^{1/2} -> more sparsity, but much computation cost!
区分
- 正则化 Regularization
- 归一化 Normalization
- 标准化 Standardization
- 权重衰减 Weight Decay: 和 \displaystyle \mathscr{l}_{2}-Norm Regularization 的区别是权重衰减直接作用在参数上,即 \displaystyle w^\prime=w-\eta\left( \frac{ \partial L }{ \partial w } +\lambda w \right), 在 SGD 中 \displaystyle \mathscr{l}_{2}-Norm 和 Weight Decay 是等价的,Adam 中不然
特别注意
- \displaystyle \mathscr{l}_{1}-Norm Normalization / \displaystyle \mathscr{l}_{1} Normalization: \displaystyle \boldsymbol{X}=\frac{\boldsymbol{X}}{\sum_{i}|x_{i}|}
Focus: \displaystyle \mathscr{l}_{1}-Norm Regularization 产生稀疏性 sparsity
Result 1. Coordinate Descent
考虑一次只对一个变量 \displaystyle \beta_{j} 进行优化,固定其他的所有变量 \displaystyle \beta_{-j};目标是最小化
推导略.
Focus: Coordinate Descent + Lasso Regularization 能把权重精确的置零
Result 2. Group Lasso L_{1,2}
将 \boldsymbol{X} 分为 J 组 \boldsymbol{X}_{1}, \boldsymbol{X}_{2},\dots,\boldsymbol{X}_{J},从而 \boldsymbol{X\beta}=\sum_{j}\boldsymbol{X}_{j}\boldsymbol{\beta}_{j},我们 Minimize
结果:组内 \mathscr{l}_2-Norm 无 sparsity,组间 \mathscr{l}_{1}-Norm 产生 sparsity,得到 col 单一维度上 sparse 的优秀矩阵,能够 GPU-friendly 地计算 (在 Im4 中说明)
Focus: Group Lasso 产生 regular sparsity
Pruning
1. Sparsity Pruning
- Matrix Approximation or Matrix Regression (将剪枝或矩阵优化问题建模为回归问题,通过最小化重构 loss 来找到最优近似矩阵)
- Sparse DNN
- Structured Sparse DNN Group lasso

- Granularity of Sparsity: irregular -> regular -> more regular -> fully-dense
2. Channel Pruning (ICCV 2017)
作者将目标 formulate 为
\mathscr{l}_0 是 NP-hard 的,于是将 \mathscr{l}_0 放松到 \mathscr{l}_1 regularization:
问题仍没有化归到线性回归,作者提出了交替下降方法,每一个 iteration 轮流优化 \boldsymbol{\beta} 和 \boldsymbol{W} (在另一者固定下). Iter: 在剪枝刚开始的时候,\boldsymbol{W} 从训练好的模型进行初始化,没有 L1 regularization 项,所有通道都还保留,多次优化 \boldsymbol{\beta};直到 ||\boldsymbol{\beta}||_{0}\leq c ;然后优化一次 \boldsymbol{W}
Im4: Sparse Conv
具有 Sparsity 的卷积层可以减小过拟合,而 sparse 的一般是 kernel,我们关注如何优化这样的计算;简化地,我们考虑 Input feature map 乘上一个列向量
Kernel Sparse Convolution
1. Naive Implementation 1
for all w[i] do: {
if w[i] = 0 then : {
Continue;
}
output feature map Y <- X * w[i]
}
问题:每步必发生分支预测,对 Pipeline 不友好
改进:Sparse Matrix Representation 
CSR (Compressed Sparse Row) & CSC (Compressed Sparse Column) 分别按 (x, y, v) 和 (y, x, v) 存,直接读就可以
问题:需要很大的 sparsity (~>67%);和量化有点冲突
2. Naive Implementation 2
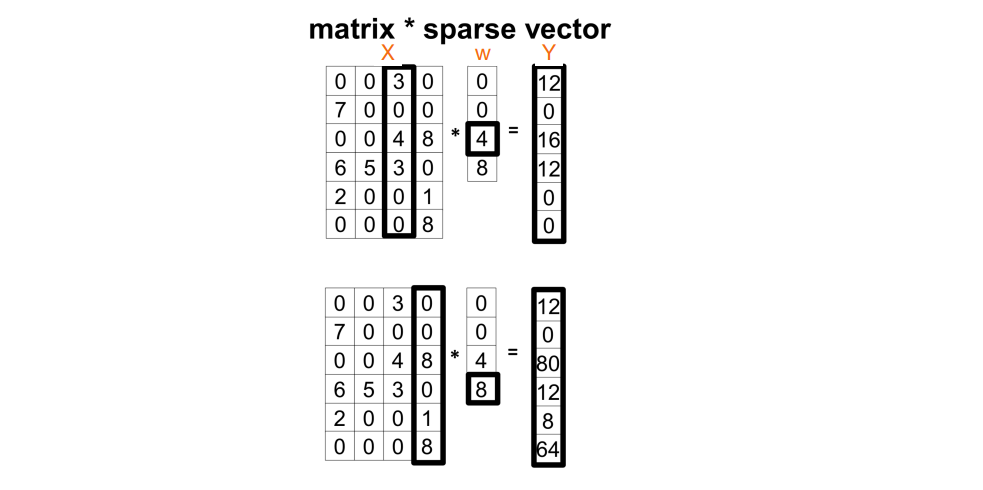
- BAD implementation for Spatial locality
- Poor memory access pattern
3. SOTA: Sparse Convolution
for each output channel n {
for j in [W.rowptr[n], W.rowptr[n+1]] {
off = W.colidx[j]; coeff = W.value[j]
for (int y = 0; y < H_OUT; ++y) {
for (int x = 0; x < W_OUT; ++x) {
out[n][y][x] += coeff * in[off + f(0,y,x)]
}
}
}
}
4. Sparse-Sparse Convolution
不推荐
- Efficient programming implementation required; (Improve pipeline efficiency)
- When sparsity(input) = 0.9, sparsity(weight) = 0.8, more than 10× speedup;
- Some other issues:
- How to be compatible with pooling layer?
- Transform between dense & sparse formats
Submanifold Sparse Convolution
专为高维稀疏数据(如3D点云、医学图像、科学计算数据)设计的卷积操作:输出位置仅在输入非零位置激活,避免对零值区域的冗余计算;输入一个 sparse 矩阵,同样输出一个 sparse 矩阵同时确保数据的交互;
原理:给定稀疏输入 X(非零位置集合 \mathcal{S}_X),卷积核 W,输出 Y 满足:
其中 \mathcal{N}(p) 是以 p 为中心的卷积窗口。
实现:
-
Spatial Hash Table
- 存储所有活跃(非零)输入点的坐标 (x,y,z) 及其特征值
- 哈希函数:h(x,y,z) = x \cdot P_1 \oplus y \cdot P_2 \oplus z \cdot P_3(\oplus 为异或,P_i 为大质数)
-
Rulebook
预计算卷积核与每个输入点的交互关系:rulebook = defaultdict(list) for p in non_zero_coords: # 遍历所有非零输入点 for offset in kernel_offsets: # 遍历卷积核偏移量 q = p + offset # 输出位置 if q in hash_table: # 仅当q在输入中活跃 rulebook[q].append((p, offset)) -
计算过程
for each output position q in rulebook: Y[q] = 0 for each (p, offset) in rulebook[q]: Y[q] += W[offset] * X[p] // 直接累加
Mo2: Low Rank Decomposition
之前我们讨论了模型压缩 (Compression) 的一种方法:构建 Sparsity;今天我们讨论另一种:低秩分解 (Low Rank Decomposition)。低秩分解欲将权重矩阵 \displaystyle W\in \mathbb{R}^{m\times n} 分解为 \displaystyle W\approx W_{1}\times W_{2},其中 \displaystyle W_{1}\in \mathbb{R}^{m\times k},W_{2}\in \mathbb{R}^{k\times n},这样可以很大降低计算量。
SVD
使用 SVD 低秩分解:
- 唯一最优分解,最小化重构误差 reconstruction error
- 任意取出 \displaystyle \boldsymbol{UDV} 中的二者乘在一起以适用于低秩分解
- \displaystyle \boldsymbol{UV} 是列正交归一 column orthonormal 的,列向量是正交的 (orthogonal) 单位 (unit) 向量
- \displaystyle \boldsymbol{D} 是对角矩阵 (diagonal)
- 降维/压缩:在 \boldsymbol{D} 中取前 k 个奇异值
- 取合适的 k:定义一列奇异值的 energy 是它们的平方和,找到 k 使 energy 下降较小
- 其他的应用例子:协同过滤 用户偏好预测 Users-to-Movies
Compute SVD
首先找到最大的一个 Principal Eigenvalue:
- 随机猜一个特征向量 eigenvector \boldsymbol{x}_{0}
- 迭代计算 \displaystyle \boldsymbol{x}_{k+1}=\frac{\boldsymbol{M}\boldsymbol{x}_{k}}{||\boldsymbol{M}\boldsymbol{x}_{k}||}
- 当 \displaystyle \Delta \boldsymbol{x}_{i}<\boldsymbol{\varepsilon} 时停止
- 依照定义计算特征值 eigenvalue \displaystyle \lambda=\boldsymbol{x}^{\top}\boldsymbol{M}\boldsymbol{x}
再找到更小的 Eigenpairs:
- 去除矩阵 \displaystyle \boldsymbol{M} 中与第一个特征 \lambda\boldsymbol{x} 相关的部分 \boldsymbol{M}*=\boldsymbol{M}-\lambda \boldsymbol{x}
- 找到 \boldsymbol{M}* 的 principal eigenpairs
- 如此迭代
利用上面计算 eigenpairs 的方法能计算 SVD:
- 假定 \displaystyle \boldsymbol{A}=\boldsymbol{U\Sigma V}^{\top}
- \displaystyle \boldsymbol{A}^{\top}=(\boldsymbol{U\Sigma V}^{\top})^{\top}=\boldsymbol{V\Sigma U}^{\top}
- \displaystyle \boldsymbol{A}^{\top}\boldsymbol{A}=\boldsymbol{V\Sigma}^{2}\boldsymbol{V}^{\top}, given that \boldsymbol{U}^{\top}\boldsymbol{U}=\boldsymbol{I} and \displaystyle \boldsymbol{\Sigma}^{2} can be element-wise
- \displaystyle \boldsymbol{A}^{\top}\boldsymbol{AV}=\boldsymbol{V\Sigma}^{2}, given that \boldsymbol{V} is also 正交的 orthonormal
- 从而计算 \boldsymbol{A}^{\top}\boldsymbol{A} 的 eigenpairs 能够找到 \boldsymbol{V}\&\boldsymbol{\Sigma}
- 同样地,\displaystyle \boldsymbol{AA}^{\top} 的 eigenpairs 给出 \boldsymbol{U}
Application to DNN
一些现有成果讨论了 SVD 在模型中的应用:
- Efficient and accurate approximations of nonlinear convolutional networks (Xiangyu Zhang et al., 2015)
- Convolutional neural networks with low-rank regularization (Cheng Tai et al., 2016)
使用 SVD,我们将 Conv layer 分解为两个连续小卷积层的组合,降低计算量
Matrix Regression Approach
SVD 解决 Matrix Approximate 是完美的,可惜 Matrix Approximate 是不完美的问题,我们更想要做 Regression;为了解决这一点,我们使用 Proposed Unified Regression ("A Unified Approximation Framework for Non-Linear Deep Neural Networks", Yuzhe Ma et al., 2019)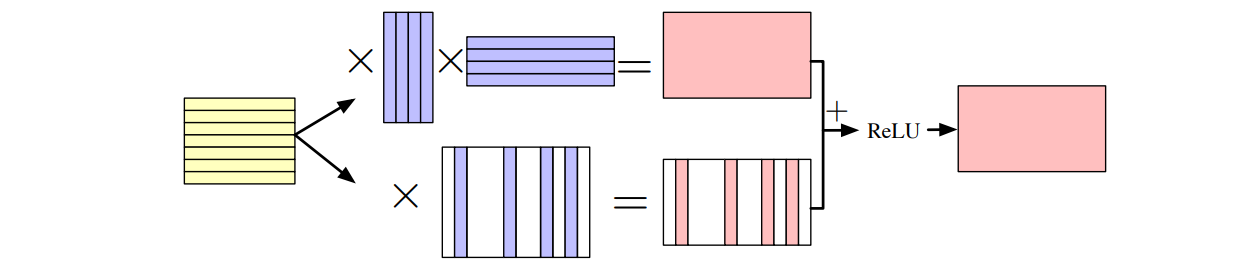
\min_{\boldsymbol{A},\boldsymbol{B}}\sum_{i=1}^{N}||\boldsymbol{Y}_{i}-\sigma((\boldsymbol{A}+\boldsymbol{B})\boldsymbol{X}_{i})||_{F}, \quad \text{s.t. }||\boldsymbol{A}||_{0}\leq S, \text{rank}(\boldsymbol{B})\leq L.
-
回归目标从优化 \boldsymbol{W}\boldsymbol{X} 优化到优化 \text{ReLU}(\boldsymbol{WX})
-
融合低秩分解和稀疏性压缩
-
Still: NP-hard 问题,以及目光只局限在一层,一次只对一层进行优化 (局部最优)
-
Relaxation: \displaystyle\min_{\boldsymbol{A},\boldsymbol{B}}\sum_{i=1}^{N}||\boldsymbol{Y}_{i}-\sigma((\boldsymbol{A}+\boldsymbol{B})\boldsymbol{X}_{i})||_{F}^{2}+\lambda_{1}||\boldsymbol{A}||_{2,1}+\lambda_{2}||\boldsymbol{B}||_{*}(其中 * 指核范数,定义为矩阵的奇异值的和,是凸函数,易于优化)
ADMM
Alternating Direction Method of Multipliers,交替方向乘子法,将复杂的优化问题通过分解为子问题、交替优化和更新变量来逐步逼近最优解。给定优化问题\min_{x, z} f(x) + g(z) \quad \text{s.t.} \quad Ax + Bz = cADMM 将问题转换为 L_\rho(x, z, y) = f(x) + g(z) + y^T(Ax + Bz - c) + \frac{\rho}{2}|Ax + Bz - c|_2^2 其中,y 是拉格朗日乘子,\rho > 0 是惩罚参数;接下来迭代求解
- 更新 x: 固定 z 和 y,最小化 L_\rho 关于 x 的部分。 x^{k+1} = \arg\min_x \left(f(x) + \frac{\rho}{2}|Ax + Bz^k - c + \frac{y^k}{\rho}|_2^2\right)
- 更新 z: 固定 x 和 y,最小化 L_\rho 关于 z 的部分。 z^{k+1} = \arg\min_z \left(g(z) + \frac{\rho}{2}|Ax^{k+1} + Bz - c + \frac{y^k}{\rho}|_2^2\right)
- 更新拉格朗日乘子 y: y^{k+1} = y^k + \rho (Ax^{k+1} + Bz^{k+1} - c)
ADMM 可以很好解决上面 Relaxation 后的优化问题。
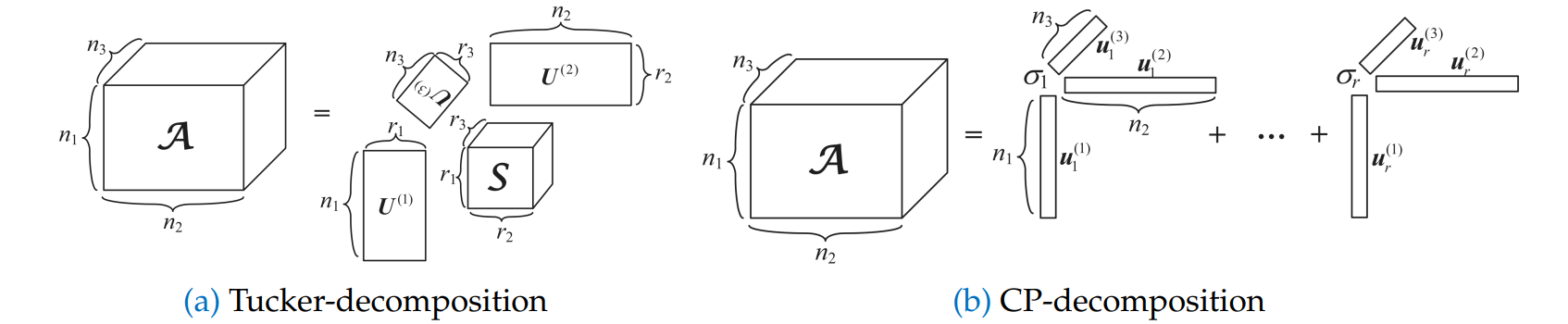
Tensor Decomposition
不做 duplication,直接对 tensor 本身做 decomposition
两种方法:
Mo3: Quantization
Fixed-Point Number
- 关于浮点数的存储:
-
- 要有三部分
-
- 要有统一形式 Normalized Form: Mantissa in [1,R) for base R
-
- IEEE Standard 754 (Sign, Expo, Mantissa)
- float32: 1, 8, 23
- float64:1, 11, 52
- Exponent 事实上是存储值-127,从而范围是 [-127,128];
Quantization Overview
- quantization 是将 param 做映射:\displaystyle Q(r)=\text{Int}\left( \frac{r}{S} \right)-Z,对结果再用 \displaystyle \hat{r}=S(Q(r)+Z) 逆回;S 和 Z 的选择依据 granularity 不同而采取 layerwise/groupwise/channelwise
- quantization 要和 byte 对齐:例如 8bit quant 刚好用 1 个 byte 存一个数,5/7/9 bit 无法对齐 memory 寻址的方式,在不定制 fpga 下就很离谱
- uniform vs. non-uniform
- uniform: 正态分布,类别不平衡
- non-uniform: 较复杂,但是可以平衡类别
- sysmetric vs. asymmetric (if Z=0)
- sysmetric 可以在乘法省掉 3/4
- Do we really need bias? No!
- quantization-aware training (QAT) vs. post-training quantization (PTQ)
- Key difference: Model parameters fixed/unfixed.
- minimum quantized value: -127(sysmetric) vs. -128(勤俭)
- -128: 一个例子,quantize & dequantize 中截断会导致 -0.00853 的 bias,累加冲向 -\infty
- -127: good
Mo4: BNN
Binary Neural Network 把模型量化为 \{-1,+1\},Ternery Neural Network 用 2bit 量化为 \{-1,0,+1\},为了对称性和稀疏性保留三值
优点:
- 乘法变成简单的 XOR/XNOR 门,再也不需要 ALU 乘法器和较大的时间开销
- 在 \mathbb{R}\times \mathbb{R} 变成 \mathbb{R}\times \mathbb{B} 时,就省掉了乘法器,mem / compute 获得 ~32x / ~2x 加成;变成 \mathbb{B}\times \mathbb{B},只需要 XNOR 门,compute 获得 ~58x 加成
Minimize Quantization Error
XNOR-NET: Imagenet classification using binary convolutional neural networks (Mohammad Rastegari et rl., 2016)
1. \mathbb{R}\times \mathbb{B}
正如先前对于 Matrix Approx 和 Matrix Regression 的讨论,这里的量化我们也希望
而不是最小化 |\boldsymbol{W}-\boldsymbol{W}_{bin}|。对后者的情况,一个朴素的想法是直接有 \boldsymbol{W}_{bin}=\text{sign}(\boldsymbol{W}),这时候的 \mathscr{l}_{1}-Norm error 达到 ~0.75;有趣的是,当加入 scaling value \alpha, 问题 formulate 为 \displaystyle \arg\min_{\boldsymbol{W}_{B},\alpha}||\boldsymbol{W}-\alpha \boldsymbol{W}_{B}||_{2}^{2},问题恰存在闭式解 \displaystyle \boldsymbol{W}_{B}=\text{sign}(\boldsymbol{W}), \text{when} \quad \alpha=\frac{1}{n}||\boldsymbol{W}||_{1}。
[!NOTE] 推导
令 J(\boldsymbol{B},\alpha)=||\boldsymbol{W}-\alpha \boldsymbol{B}||_{2},我们的任务是解决优化问题 \displaystyle \alpha^{*},\boldsymbol{B}^{*}=\arg\min_{\alpha,\boldsymbol{B}}J(\boldsymbol{B},\alpha)。
展开上式有 \displaystyle J(\boldsymbol{B},\alpha)=\alpha^{2}\boldsymbol{B}^{\top}\boldsymbol{B}-2\alpha \boldsymbol{W}^{\top}\boldsymbol{B}+\boldsymbol{W}^{\top}\boldsymbol{W}, since \displaystyle \boldsymbol{B}\in\{-1, +1\}^{n};从而我们知道 \displaystyle \boldsymbol{W}^{\top}\boldsymbol{W} 和 \displaystyle \boldsymbol{B}^{\top}\boldsymbol{B}=n 都是 Constant! 问题化为 \displaystyle \boldsymbol{B}^{*}=\arg\max_{\boldsymbol{B}}\boldsymbol{W}^{\top}\boldsymbol{B}。局部和全局最优地,让 \boldsymbol{B}_{i}=+1 if \boldsymbol{W}_{i}\geq{0},\boldsymbol{B}_{i}=-1 if \boldsymbol{W}_{i}<0,换言之,\displaystyle \boldsymbol{B}^{*}=\text{sign}(\boldsymbol{W}),又有 \displaystyle \frac{ \partial J }{ \partial \alpha }=0 时 \displaystyle \alpha^{*}=\frac{\boldsymbol{W}^{\top}\boldsymbol{B}^{*}}{n}=\frac{\boldsymbol{W}^{\top}\text{sign}(\boldsymbol{W})}{n}=\frac{\sum|\boldsymbol{W}_{i}|}{n}=\frac{1}{n}||\boldsymbol{W}||_{1}。
遵循以上原理的 Quant-aware Training 过程是
- 随机初始化权重 \displaystyle \boldsymbol{W}
- 得到量化权重 \displaystyle \boldsymbol{W}_{B}=\text{sign}(\boldsymbol{W}), \displaystyle \alpha=\frac{||\boldsymbol{W}||_{1}}{n}
- 在认为 \displaystyle \boldsymbol{W}=\alpha \boldsymbol{W}_{B} 下计算 loss \displaystyle \frac{ \partial C }{ \partial \boldsymbol{W} }, 更新 \displaystyle \boldsymbol{W}=\boldsymbol{W}-\frac{ \partial C }{ \partial \boldsymbol{W} }
- 回到第 2 步
比 Full-Precision 的性能损失很小。
2. \mathbb{B}\times \mathbb{B}
现在认为 \displaystyle \boldsymbol{X}\odot\boldsymbol{W}\approx \beta \boldsymbol{X}_{B}\odot\alpha \boldsymbol{W}_{B} 并最小化误差,过程完全同上而得到 \displaystyle \boldsymbol{X}_{B}=\text{sign}(\boldsymbol{X}), \displaystyle \boldsymbol{W}_{B}=\text{sign}(\boldsymbol{W})
Accurate Binary CNN
3-bit quant 的一种实现方法,把 3-bit 值竖着存进存储里,这样无论如何都对齐了;但是要重载加法和乘法操作,可能带来一定的性能损失;或者写进 FPGA 里完全客制化一个 3-bit 的操作
Mo5: Knowledge Distillation
Distillation
- 我们从世界学习知识的方式不仅是 Groundtruth, Positive/negative, Masked data; 从一个婴儿一出生开始就接受世界上的各种信息,因此迁移学习 transfer learning 和蒸馏 distillation 对增强模型对各类数据的理解总是必要的
- 基于图片的低秩假设,我们希望对图片做各种 permutation 以确保模型提取的是有效信息,这也对模型的 distillation 如何学到真正的有效特征有帮助
- 知识蒸馏由最小化 Teacher network 和 Student network 之间的 KL divergence (Kullback-Leibler divergence) 实现,定义 \displaystyle D_{\text{KL}}=\sum_{x\in \mathscr{X}}P(x)\log\left( \frac{P(x)}{Q(x)} \right),推导得到等价于最小化 KD Loss:\mathscr{L}_{\text{KD}}=-\sum_{i=1}^{N}p(\boldsymbol{x} _{i})\log(q(\boldsymbol{x} _{i}))其中,p(\boldsymbol{x} _{i})=\frac{\exp\left( \frac{\boldsymbol{v}_{i}}{\tau} \right)}{\sum_{j=1}^{C}\exp\left(\frac{\boldsymbol{v}_{j}}{\tau} \right)}, q(\boldsymbol{x} _{i})=\frac{\exp\left( \frac{\boldsymbol{z}_{i}}{\tau} \right)}{\sum_{j=1}^{C}\exp\left( \frac{\boldsymbol{z}_{j}}{\tau} \right)}这里 \tau 是温度,C 是类别数;总而言之,\mathop{\arg\min}_{\theta}\mathscr{L}_{\text{KD}} = \mathop{\arg\min}_{\theta}\mathscr{L}_{\text{KL}}
Knowledge Modeling
- Response-Based Knowledge:
Data -> Teacher -> Logits ->
Data -> Student -> Logits ->
Distillation Loss - Feature-Based Knowledge: 使用某种衡量相似性的函数 \mathscr{L}_{F},在教师和学生的特征 shape 不同的情况下应用变换,问题 formulate 为 \displaystyle L_{FeaD}(f_{t}(x)),f_{s}(x))=\mathscr{L}_{F}(\phi_{t}(f_{t}(x)), \phi_{s}(f_{s}(x)))
- Relation-Based Knowledge: 我们试图衡量模型中间某些层关系的相似性,formulation: \displaystyle L_{\mathrm{RelD}}(f_{t},f_{s})=\mathscr{L}_{R}(\Phi_{t}(\dot{f_{t}},\hat{f_{t}}),\Phi_{s}(\dot{f_{s}},\hat{f_{s}}))
Distill Method
- Online/Offline Distillation
- Self Distiilation (非常扯)
- Ensemble KD
- Data Free KD
Mo6: Network Architecture Search
在 NAS 中,我们要关注的主要问题是
- 解空间约束 (不能跑出来乱七八糟的结构)
- 评估指标 Metrics (特别是除了 task metrics, 还要加上 #FLOPs 和 #Params)
1. Optimization
一个朴素的想法是把 NAS 看成一个 hyperparameter optimization 的问题,这些超参包括 (1) hidden states dims (2) operations (3) combination strategy (4) cell params;2017年,Google 使用 RL 策略优化 (因为不可导!),引入一个 RNN Controller 给出超参,用这些超参训练一个 child network,以它在 task 上的 metric 为 reward 交还给 RNN Controller 更新。formulate 为
消耗资源巨大效果也一般。
2017年 Real, Moore, et al. 提出 Mutation steps, such as adding, changing or removing a layer, 采用遗传算法 Evolution 优化模型结构
Bayesian Optimization ...
2. Differentiable Search
如何把搜索解空间放松到连续:认定每一个层之间都有一个带权值的边,希望优化这个权值,最后二值化;bi-level optimization formulate as
NAS 现在不那么重要,大力出奇迹,模型的性能现在主要由数据质量决定。